Eric Archer sent in a question on Bayesian logistic regression. I don't really have much to say on this one, but since it's about dolphins I'll give it a try anyway. First Eric's question, then my reply.
Continue reading Still more on dolphin fetuses.


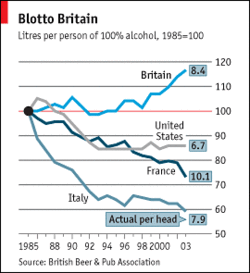
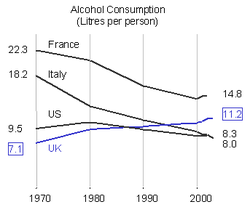
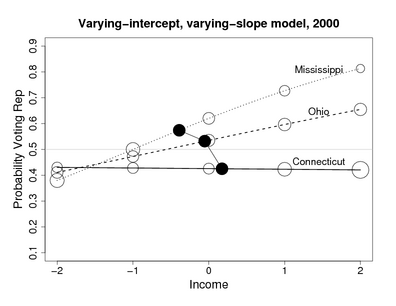
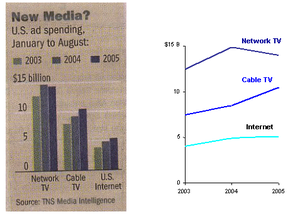
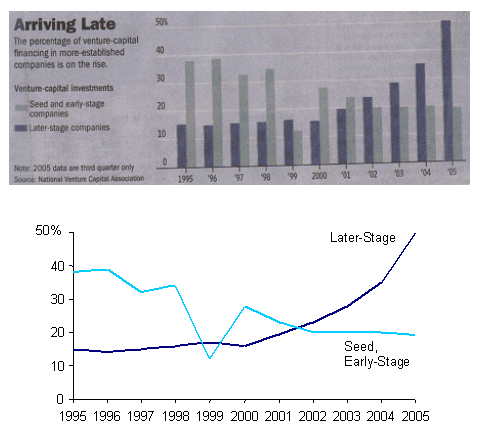
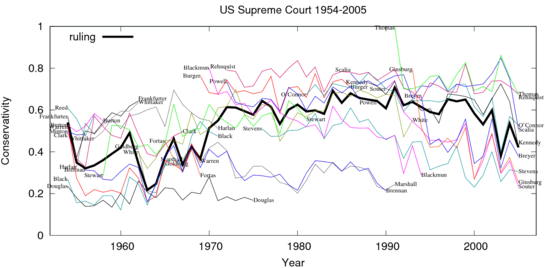
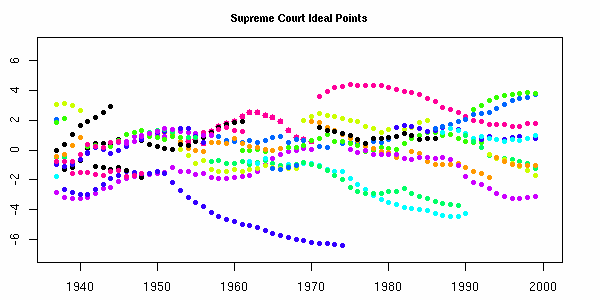
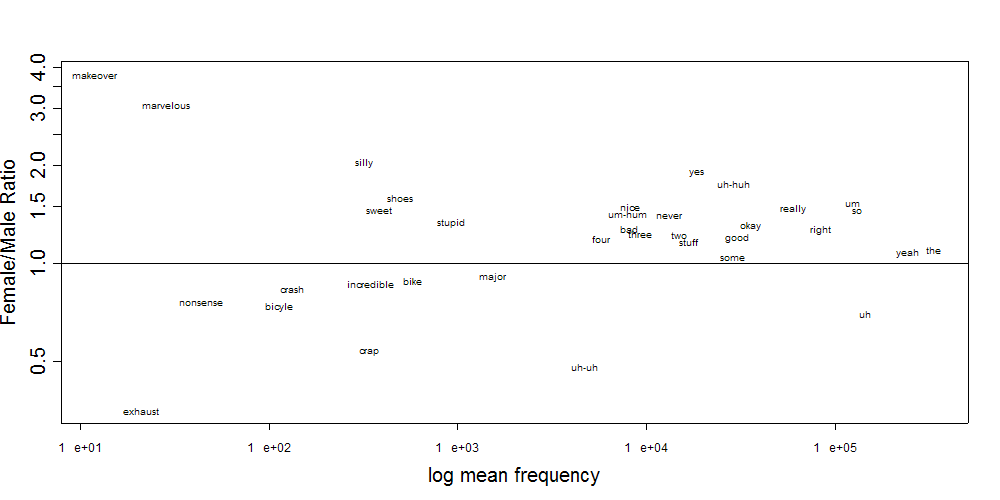
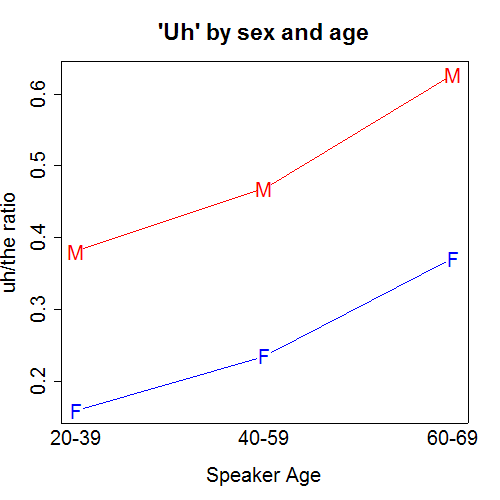
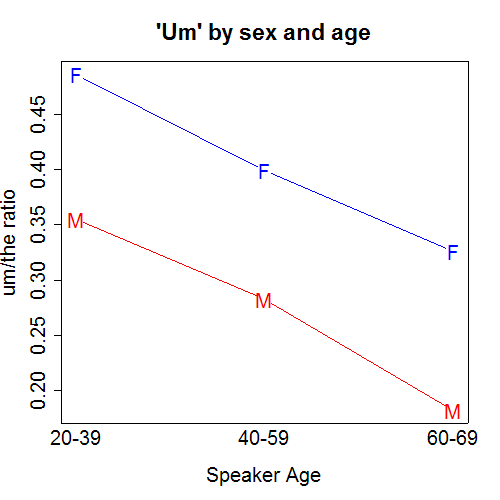
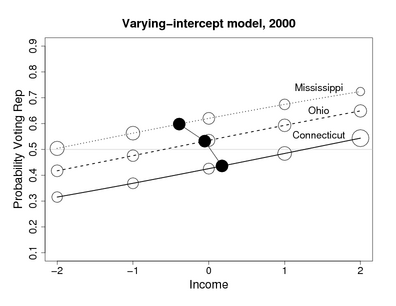



Recent Comments