I'm planning to teach a new course on statistical graphics next spring.
Background:
Graphical methods play several key roles in statistics:
- "Exploratory data analysis": finding patterns in raw data. This can be a challenge, especially with complex data sets.
- Understanding and making sense of a set of statistical analyses (that is, finding patterns in "cooked data")
- Clear presentation of results to others (and oneself!)
Compared to other areas of statistics, graphical methods require new ways of thinking and also new tools.
The borders of "statistical graphics" are not precisely defined. Neighboring fields include statistical computing, statistical communication, and multivariate analysis. Neighboring fields outside statistics include computer programming and graphics, visual perception, data mining, and graphical presentation.
Structure of the course:
Class meetings will include demonstrations, discussions of readings, and lectures. Depending on their individual interests, different students will have to master different in-depth topics. All students will learn to make clear and informative graphs for data exploration, substantive research, and presentation to self and others.
Students will work in pairs on final projects. A final project can be a new graphical analysis of a research topic of interest, an innovative graphical presentation of important data or data summaries, an experiment investigating the effectiveness of some graphical method, or a computer program implementing a useful graphical method. Each final project should take the form of a publishable article.
The primary textbook will be R Graphics, by Paul Murrell (to be published Summer, 2005).
See below for more information on the course; also see here for a related course by Bill Cleveland (inventor of lowess, among other things). Any further suggestions would be appreciated.
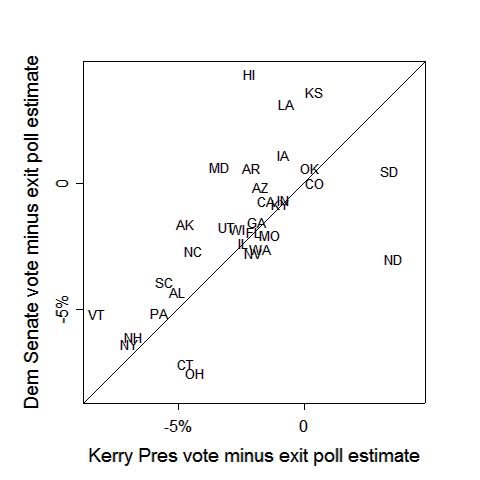
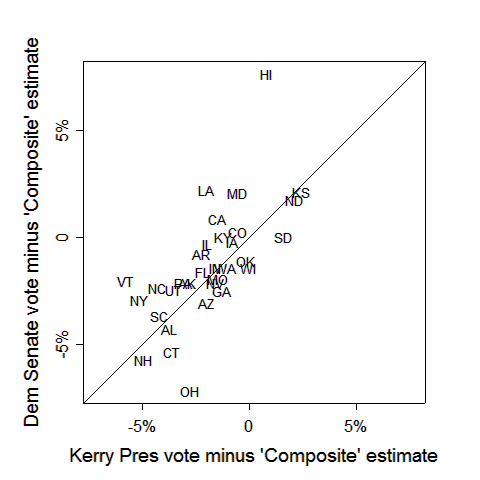
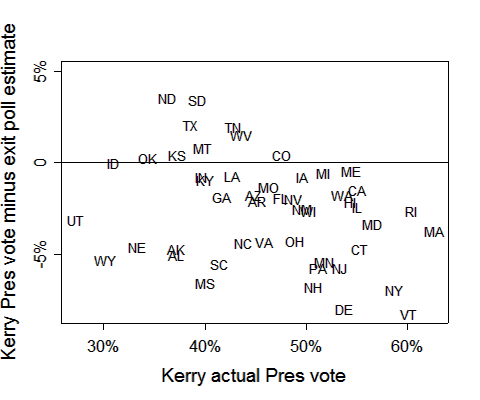
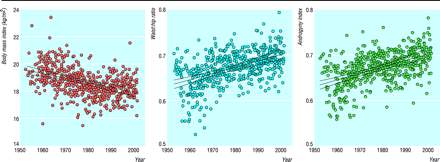
.png)



{kind=link}