This is actually the curve John Kastellec estimated for 2006 using the 2004 election data (it's in our paper):
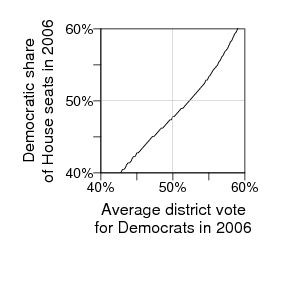
But the curve as estimated from the 2006 elections (once we have all the data in a convenient place) will look similar. It's basically consistent with what happened (with 56% of the vote, the Democrats got a bit more than 53% of the seats).
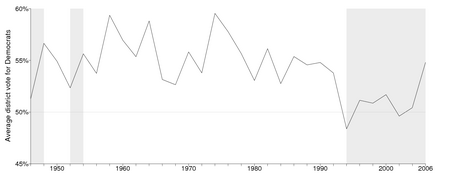
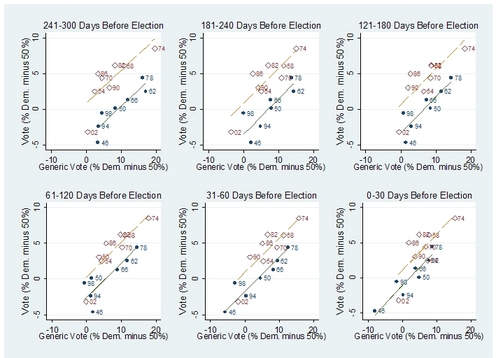
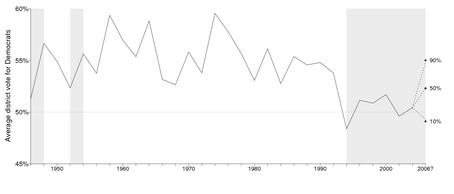
The historical pattern of votes is shown here. In 2006, the Democrats matched their historical performance in the 1960s-1980s in votes, but not in seats.
Our 1991 paper has more background on historical seats-votes curve.




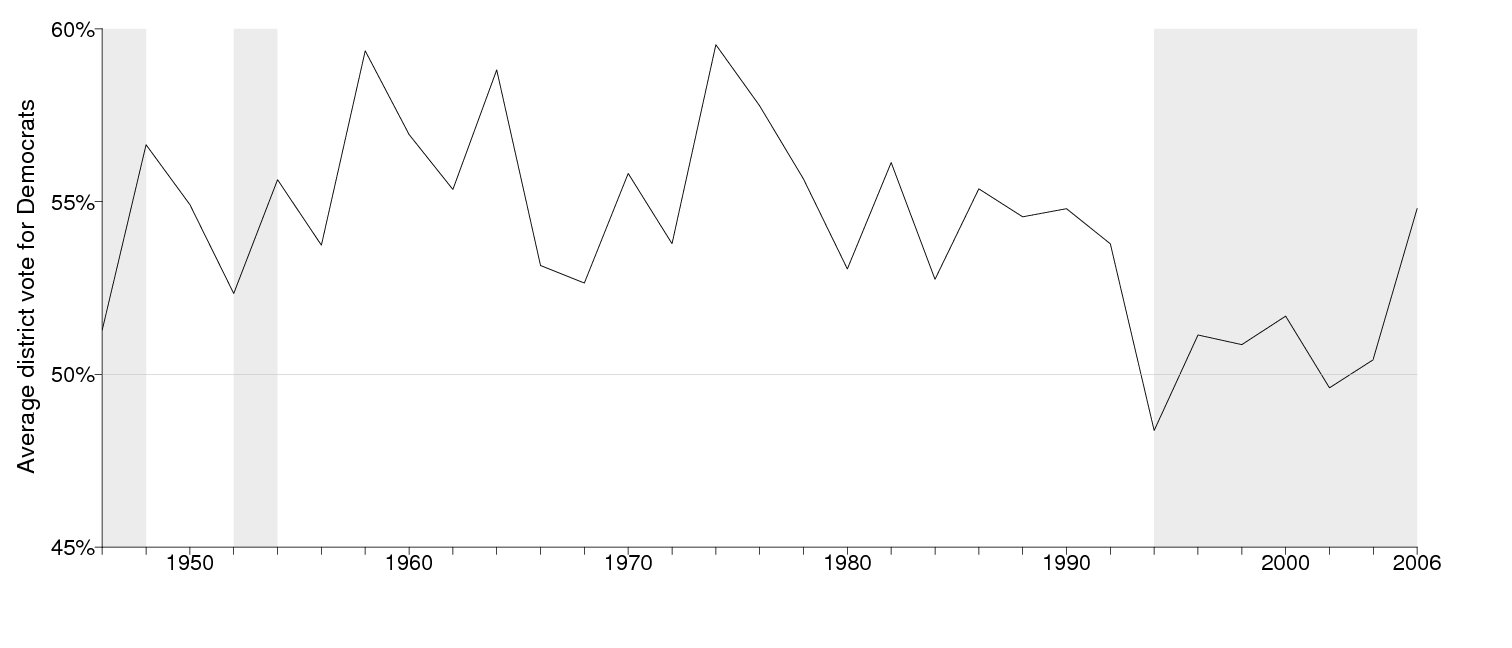{kind=link}
{kind=link}
{kind=link}
{kind=link}
Recent Comments