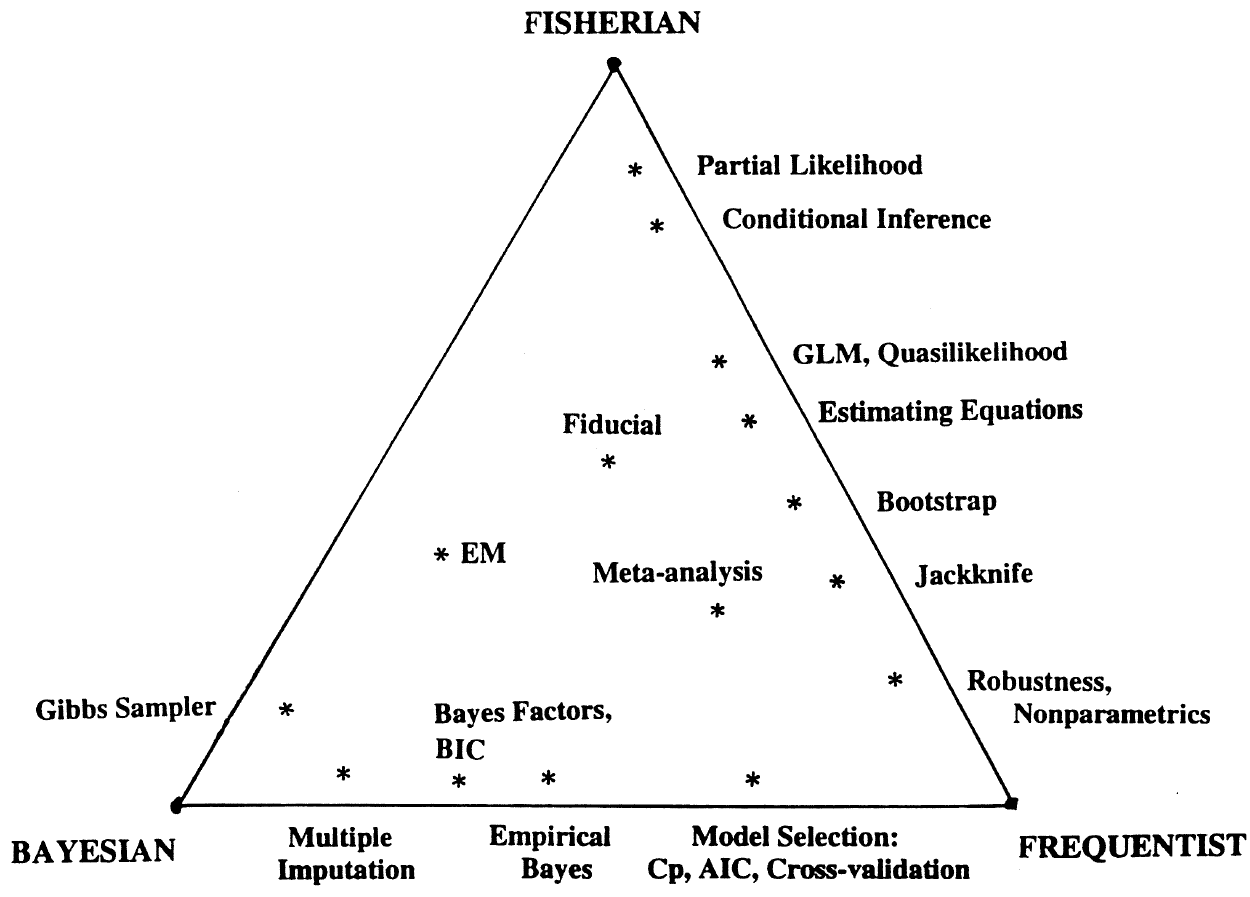
Jeff Heer reports that IBM has released their Many Eyes platform for browser-based data analysis. I have already written about Swivel, and there is another similar system called Data 360. However, the Many Eyes seems to be the most impressive of all, with very clean visualizations and numerous types of graphs, including, for example, social networks and maps.


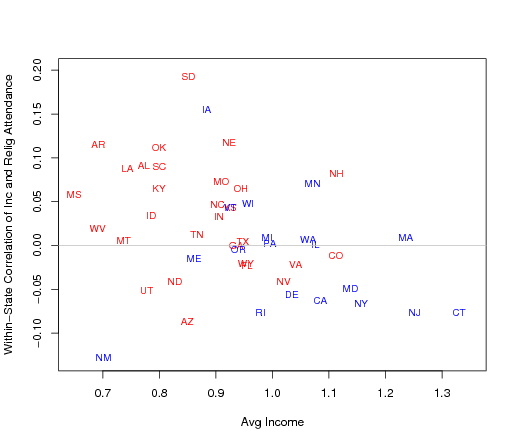
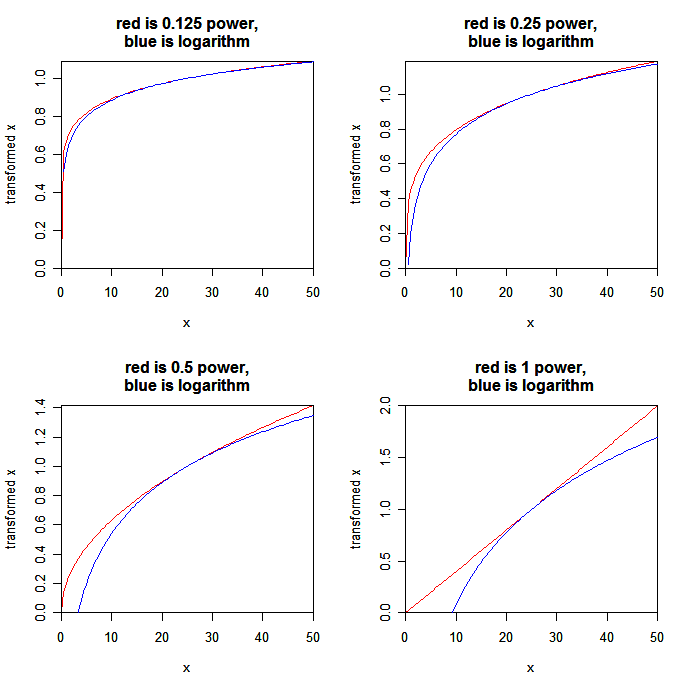


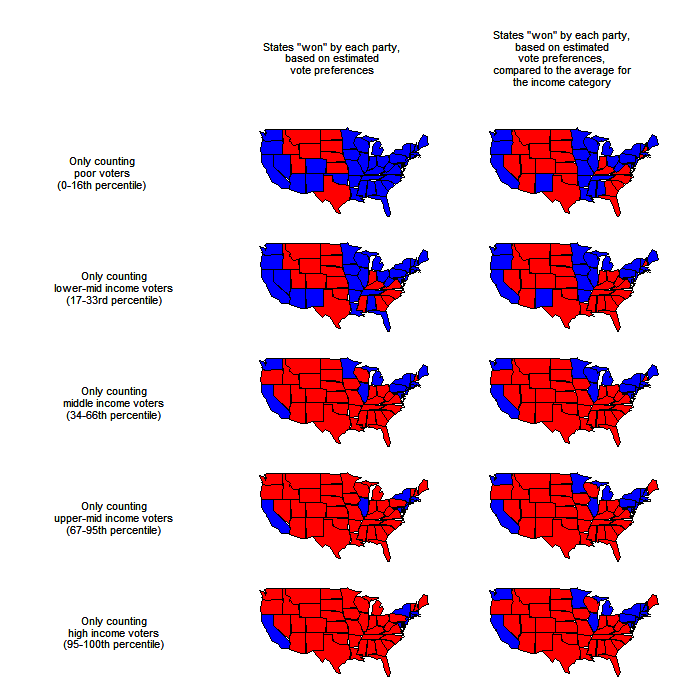
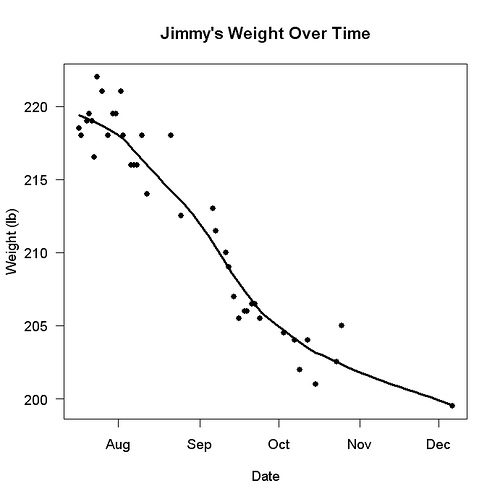
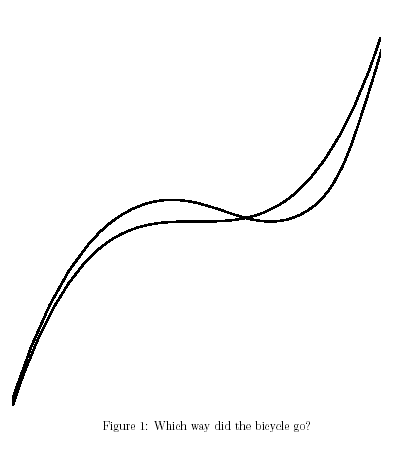
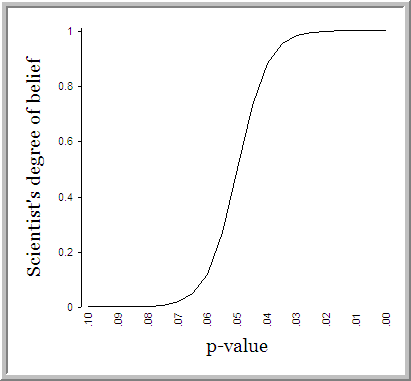
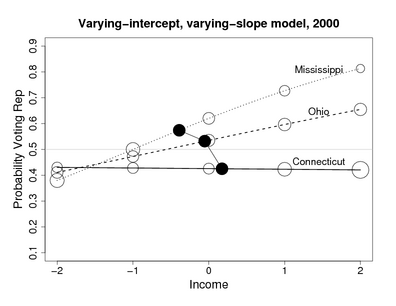






{kind=link}