One thing I learned in econ class in 11th grade was that government policy should be counter-cyclical (spending more in recessions and cutting back in boom times), but that there’s a lot of pressure to be pro-cyclical, which will tend to exacerbate business cycles. (Except I suppose they didn’t say “exacerbate” in 11th grade.) At a personal level, too, it’s natural to spend more when we have more and cut back when we aren’t doing so well. Every now and then you hear about a “rainy day fund” but my general impression is that these are never big enough to counter the business cycle.
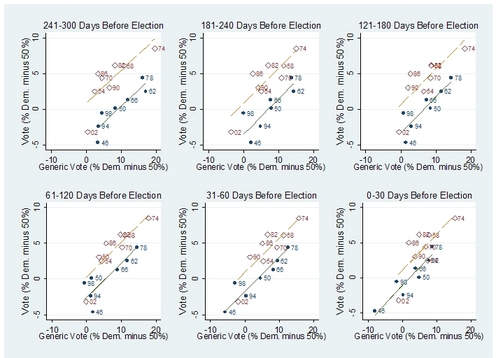
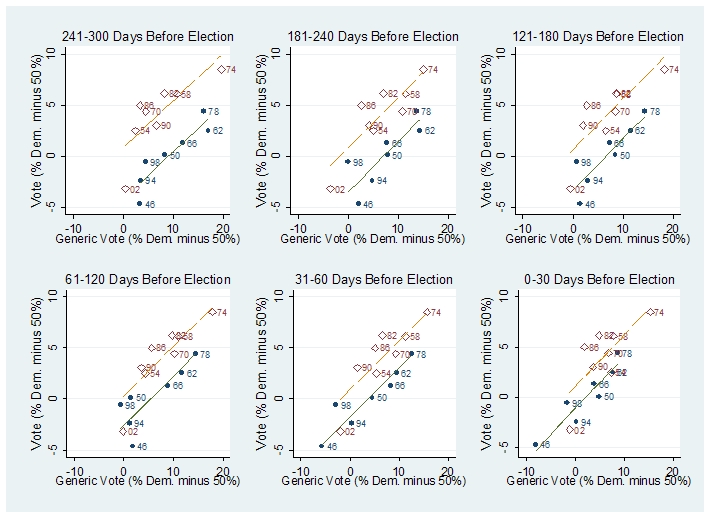
Political parties seem to apply a similar pro-cyclical behavior in their congressional election campaigns. Consider 2008. . .
























{kind=link}
Recent Comments