In a comment here, Martin Termouth cited this report from Nature, "One in three scientists confesses to having sinned."
But what are these sins? Here's the relevant table:
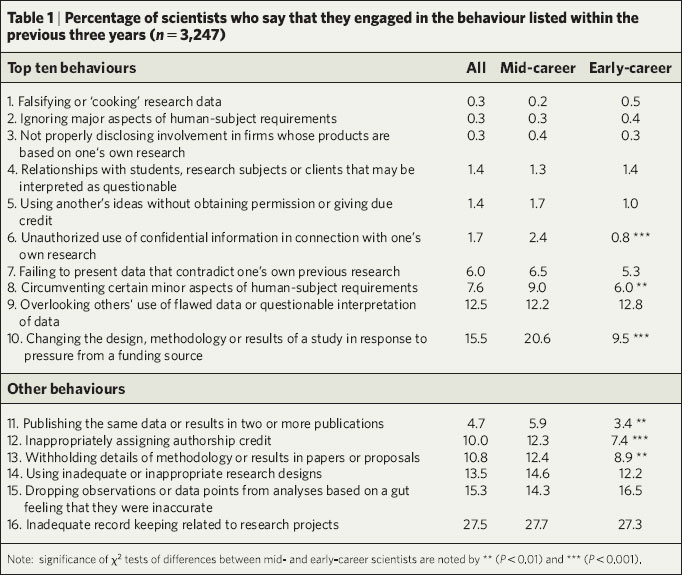
This looks pretty bad, until you realize that the rarest behaviors, which are also the most severe, are at the top of the table. The #1 "sin," admitted-to by 15.5% of the respondents, is "Changing the design, methodology or results of a study in response to pressure from a funding source." But is that a sin at all? For example, I've had NIH submissions where the reviewers made good suggestions about the design or data analysis, and I've changed the plan in my resubmission. This is definitely "pressure"--it's not a good idea to ignore your NIH reviewers--but not improper at all.
From the other direction, as an NSF panelist I've made suggestions for research proposals, with the implication that they better think very hard about alternative designs or analyses if they want to get funding. This all seems proper to me. Of course, I agree that it's improper to change the results of a study in response to pressure. But, changing the design or methodology, that seems OK to me.
Now let's look at the #2 sin, "Overlooking others' use of flawed data or questionable interpretation of data." This is not such an easy ethical call. Blowing the whistle on frauds by others is a noble thing to do, but it's not without cost. My friend Seth Roberts has, a couple times, pointed out cases of scientific fraud (here's one example), and people don't always appreciate it. Payoffs for whistleblowing are low and the costs/risks are high, so I'd be cautious about characterizing "Overlooking other's use of flawed data..." as a scientific "sin."
Now, the #3 sin, "Cirumventing certain minor aspects of human-subjects requirements." I agree that this could be "questionable" behavior. Although I'm not quite sure if "circumventing" is always bad. It's sort of like the difference between "tax evasion" (bad) and "tax avoidance" (OK, at least according to Judge Learned Hand).
Taking out these three behaviors leaves 11.4%, not quite as bad as the "more than a third" reported. (On the other hand, these are just reported behaviors. I bet there's a lot more fraud out there by people who wouldn't admit to it in a survey.)
If you've read this far, here's a free rant for you!
P.S. When you click on a Nature article, a pop-up window appears, from "c1.zedo.com", saying "CONGRATULATIONS! YOU HAVE BEEN CHOSEN TO RECEIVE A FREE GATEWAY LAPTOP . . . CLICK HERE NOW!." Is this tacky, or what? I thought the British were supposed to be tasteful!







Recent Comments